Order in archive and compression ratio (2)
This is a follow-up on the previous entry on observing the results of changing the file order when creating compressed archives. Shuffling the files before adding them to the archive and compressing will give files of different sizes. The following diagrams represent the distributions of the file sizes after creating 560000 archives randomly.
The distribution for tar.gz files seems to follow a normal law. On this test, the gap between the smallest file and the biggest file is about 4%:
The distribution for tar.gz files seems to follow a normal law. On this test, the gap between the smallest file and the biggest file is about 4%:

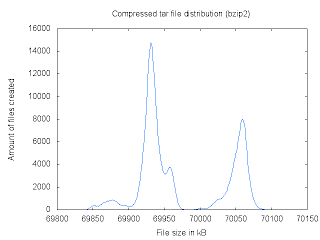
The distribution for bzip2 files is dependent on the input files. Different files will produce different curves. Also, the gap between the smallest and biggest files was found to be less than 0.5%:
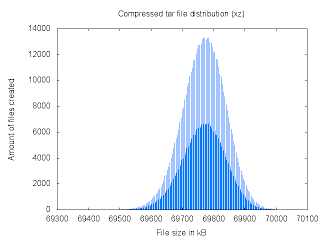
The amount of bytes of the files compressed using xz (tar cJvf) is an even number (69700, 69702, 69704, ...). This is causing the discontinuity in the following curve (and the optical illusion). Also, the gap between the smallest and biggest files was more than 0.9%.
Changing the file order in the archive does change the size of the compressed archives, but the question that comes naturally is "by how much?". The amount of files and the compression speed make it a bit difficult to perform an exhaustive search (67!). To make a oneself a better idea of the bounds, using a local search such as simple hill-climbing search is therefore a good idea. Here are the results after compressing about 50000 files:
On the bzip2 search, the hill climbing search did not increase the bounds substantially. This suggests that the search got trapped in local minimums, which is not really surprizing given the shape of the distribution. Since Waf uses bzip2 compression, it will be interesting to try another kind of local search to improve the bounds, and try to understand what makes some archives more compressible than others.