Cost of starting processes on multiple cores
Ten years ago most computers had one or two CPU cores and quite a few of us were hoping that performance would not be a concern in the future. News have been a bit disappointing, as processors may well have more cores, but they are not getting much faster. New Python interpreters would overcome the weaknesses of CPython, but they are not as fast and usable for the time being (Pypy, Jython, IronPython). This slower progress has also helped the development of cloud solutions as older hardware usage remains profitable.
Software is growing in complexity and the build tools have not escaped the trend. As anyone can write a build system, quite a lot of tools have been written, but only a few new ideas have appeared over the years. Waf has been using a reverse dependency graph since about 2006 for example, and small enhancements such as cleaning up stale files as part of the build were already implemented as extensions years ago.
An innovative idea currently explored in wonderbuild is to write the build scripts as Python generators in order to limit the amount of "busy wait". It seems to yield interesting performance benefits on benchmarks at least. The Waf source code can be modified to use generators (modifications in Task.py and Runner.py) but the performance benefits are not significant, and writing all Python functions as generators is complicated. The Python asyncio module is also limited to Python >= 3.4.
At least, experimenting with the benchmark files has revealed that a significant amount of time can be spent in spawning processes. Build performance used to degrade approximately linearly with build tool performance years ago on a single core system, but now the effects become excessively clearly visible with multiple cores.
The following picture illustrates the hardware thread activity on an 4-core hyperthreaded CPU (i7-4770K) during two builds (link to the benchmark). The first build is unable to spawn sufficient processes to keep the hardware fully busy. It also appears that the occupancy degrades over time; this is probably due to the growing memory usage of the Python process.
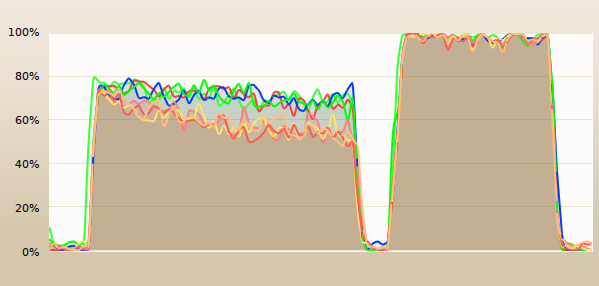
The second build was obtained by enabling a new Waf extension called prefork in the build process. Instead of spawning processes as needed, the extension would start slave processes, and reserve a pool of connections to them. When needed, threads in the build process would just call the slaves to launch the compiler processes for them and to return the exit status and any additional text produced during the execution (build outputs can become garbled if all processes write at the same time).
The second build on the picture was nearly twice as fast as the first one (30s -> 17s), and the difference on larger benchmark builds seems to improve (2m7 -> 0m55). Yet, this is unlikely to help so much in practice: on the Samba builds the gap is much smaller (~5%: 1m50 -> 1m45). This is probably due to the build tasks taking a much longer time to complete.
I would be curious to experiment on hardware featuring a lot of cores though (128? 256?), so if you can access or provide access to such hardware, feel free to drop a comment, or to join the discussion on #waf on freenode.