Make your own build system with the Waf framework
Are you dissatisfied with Python? Do you prefer XML, YAML or JSON for build scripts? Or maybe you think you can create a better domain-specific language for build scripts? Before trying to invent new build system from scratch, try re-using the Waf framework.
Waf 1.6 features a new customization system for the Waf files, which means that the Waf libraries can be re-used easily without forcing the use of wscript files. Here is how to create a waf file that will print "Hello, world!" and stop:
Here is for example a script that may be used to read files named "bbit":
Waf 1.6 features a new customization system for the Waf files, which means that the Waf libraries can be re-used easily without forcing the use of wscript files. Here is how to create a waf file that will print "Hello, world!" and stop:
waf configureThe resulting waf file will then exhibit the following lines of code:
--prelude=$'\tprint("Hello, world!")\n\tsys.exit(0)\n'
if __name__ == '__main__':Writing code in the prelude section is a bit complicated, but the execution can be delegated to a separate waf tool. For example, with a tool named bbdlib featuring a function named "start":
print("Hello, world!")
sys.exit(0)
from waflib import Scripting
Scripting.waf_entry_point(cwd, VERSION, wafdir)
./waf-light configure build --tools=$PWD/bbdlib.pyThe file bbdlib.py will be included in the resulting waf file as waflib/extras/bbdlib.py, so the resulting code has to use an import. Also, the original parameters (current working directory, waf version and waf directory) are propagated as they can be useful in the execution:
--prelude=$'\tfrom waflib.extras import bbdlib\n\tbbdlib.start(cwd, VERSION, wafdir)\n\tsys.exit(0)'
if __name__ == '__main__':
from waflib.extras import bbdlib
bbdlib.start(cwd, VERSION, wafdir)
sys.exit(0)
from waflib import Scripting
Scripting.waf_entry_point(cwd, VERSION, wafdir)
Here is for example a script that may be used to read files named "bbit":
import os, sys, impHere are a few points to keep in mind:
from waflib import Context, Options, Configure, Utils, Logs
def start(cwd, version, wafdir):
try:
os.stat(cwd + '/bbit')
except:
print('call from a folder containing "bbit"')
sys.exit(1)
Logs.init_log()
Context.waf_dir = wafdir
Context.top_dir = Context.run_dir = cwd
Context.out_dir = os.path.join(cwd, 'build')
Context.g_module = imp.new_module('wscript')
Context.g_module.root_path = os.path.join(cwd, 'bbit')
Context.Context.recurse = lambda x, y: getattr(
Context.g_module, x.cmd, Utils.nada)(x)
Context.g_module.configure = lambda ctx: ctx.load('g++')
Context.g_module.build = lambda bld: bld.objects(
source='main.c')
opt = Options.OptionsContext().execute()
do_config = 'configure' in sys.argv
try:
os.stat(cwd + '/build')
except:
do_config = True
if do_config:
Context.create_context('configure').execute()
if 'clean' in sys.argv:
Context.create_context('clean').execute()
if 'build' in sys.argv:
Context.create_context('build').execute()
- A module simulating a wscript file is created dynamically to simulate the execution of a top-level wscript file. This script attempts to re-use as much code as possible, but some configuration tests illustrate how to bypass all restrictions.
- Although a few variables are shared by several classes (Context.top_dir), the initialization is not required. One might want to subclass the BuildContext class and start with a nearly empty script.
- The commands configure, clean and build are implemented for the illustration. In practice it may be easier to create command subclasses for specific purposes.
Top-level source files
A really weird scenario was discussed on IRC recently: declare a C++ program by referencing only the main.cpp file, and have the build system add other source files by looking at the includes. For example:
The request was a bit surprising, because in large projects it is usually the norm to declare the source files explicitly to avoid confusing other developers. Even globs are used rarely in practice, as they conceal the exact source files to use.
For a single developer working on his project it probably does not matter anyhow, so an example was added in the playground area. Here is the link to the example.
- main.cpp includes foo.h
- foo.h has a corresponding foo.cpp file
- foo.cpp includes a bar.h file
- the file bar.h has a corresponding bar.cpp file
The request was a bit surprising, because in large projects it is usually the norm to declare the source files explicitly to avoid confusing other developers. Even globs are used rarely in practice, as they conceal the exact source files to use.
For a single developer working on his project it probably does not matter anyhow, so an example was added in the playground area. Here is the link to the example.
Code generators and unknown files
Code generators may lead to complicated scenarios, especially when they create files which are not known in advance. The usual process consists in adding specific task classes which will read the files after the execution, create the corresponding node objects, and update the node signatures.
When the generated files are kept in the source directory (and redistributed with the source code), a more simple (and less correct) solution is still possible. In the following example, a code generator will create C files in the folder named "generated":
The POST_LAZY scheme will force the build groups to be processed sequentially, so the total of tasks to execute will be incorrect. For example, the progress bar will reach 100% each time a build group is processed. For example, the task counter will jump from 1 to 5:
The feature find_them is will complete the program source list after code generator is executed, as adding source=bld.ant_glob('**/*.c') would only read old files.
The code source for this example has been added to the playground folder.
When the generated files are kept in the source directory (and redistributed with the source code), a more simple (and less correct) solution is still possible. In the following example, a code generator will create C files in the folder named "generated":
def options(opt):The first rule create_files will remove any C file from the generated directory, and add new ones with random names. The generated files, and main.c will be compiled into a program, but only after the files are correctly created.
opt.load('compiler_c')
def configure(cnf):
cnf.load('compiler_c')
def build(bld):
from waflib import Build
bld.post_mode = Build.POST_LAZY
def create_files(tsk):
out = tsk.generator.path.make_node('generated')
from waflib import Utils
for x in out.ant_glob('*.c'):
x.delete()
import random
for x in range(2):
num = random.randint(0, 2**31)
k = out.make_node('test%d.c' % num)
k.write('int k%d = %d;' % (num, num))
bld(rule=create_files, source='wscript', name='codegen')
bld.add_group()
bld.program(features='find_them',
source=['main.c'], target='app')
from waflib.TaskGen import feature, before
from waflib import Utils
@feature('find_them')
@before('process_source')
def list_the_source_files(self):
self.source = Utils.to_list(self.source) +
self.path.ant_glob('generated/*.c')
The POST_LAZY scheme will force the build groups to be processed sequentially, so the total of tasks to execute will be incorrect. For example, the progress bar will reach 100% each time a build group is processed. For example, the task counter will jump from 1 to 5:
12:52:14 /playground/codegen> waf clean build
'clean' finished successfully (0.005s)
Waf: Entering directory `/playground/codegen/build'
[1/1] codegen: wscript
[2/5] c: main.c -> build/main.c.1.o
[3/5] c: generated/test2017594948.c -> build/generated/test2017594948.c.1.o
[4/5] c: generated/test277184706.c -> build/generated/test277184706.c.1.o
[5/5] cprogram: build/main.c.1.o build/generated/test2017594948.c.1.o build/generated/test277184706.c.1.o -> build/app
Waf: Leaving directory `/playground/codegen/build'
'build' finished successfully (0.235s)
The feature find_them is will complete the program source list after code generator is executed, as adding source=bld.ant_glob('**/*.c') would only read old files.
The code source for this example has been added to the playground folder.
Order in archive and compression ratio (2)
This is a follow-up on the previous entry on observing the results of changing the file order when creating compressed archives. Shuffling the files before adding them to the archive and compressing will give files of different sizes. The following diagrams represent the distributions of the file sizes after creating 560000 archives randomly.
The distribution for tar.gz files seems to follow a normal law. On this test, the gap between the smallest file and the biggest file is about 4%:
The distribution for tar.gz files seems to follow a normal law. On this test, the gap between the smallest file and the biggest file is about 4%:

The distribution for bzip2 files is dependent on the input files. Different files will produce different curves. Also, the gap between the smallest and biggest files was found to be less than 0.5%:
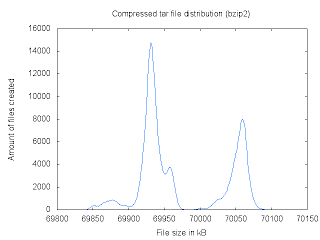
The amount of bytes of the files compressed using xz (tar cJvf) is an even number (69700, 69702, 69704, ...). This is causing the discontinuity in the following curve (and the optical illusion). Also, the gap between the smallest and biggest files was more than 0.9%.
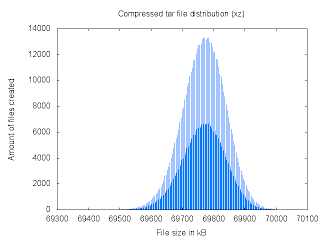
Changing the file order in the archive does change the size of the compressed archives, but the question that comes naturally is "by how much?". The amount of files and the compression speed make it a bit difficult to perform an exhaustive search (67!). To make a oneself a better idea of the bounds, using a local search such as simple hill-climbing search is therefore a good idea. Here are the results after compressing about 50000 files:
On the bzip2 search, the hill climbing search did not increase the bounds substantially. This suggests that the search got trapped in local minimums, which is not really surprizing given the shape of the distribution. Since Waf uses bzip2 compression, it will be interesting to try another kind of local search to improve the bounds, and try to understand what makes some archives more compressible than others.
Order in archive and compression ratio (1)
The following example was recently added to the Waf directory to experiment with lots of tasks created by make-like rules. The tasks from the example will perform the following operations:
- Create compressed archives from the same files taken in random order (shuffled)
- Measure the compressed file sizes, and add the values into a main data file
- Compute the file size distribution from the main data file
- Create a gnuplot script to represent the distribution
- Use the gnuplot script to create pictures
The files used in the example are the python files from Waf, and the archives are created in the tar format, which are compressed by gzip or bzip2. After creating a bit more than 300000 compressed files, the distribution of the gzip files will look like the following:
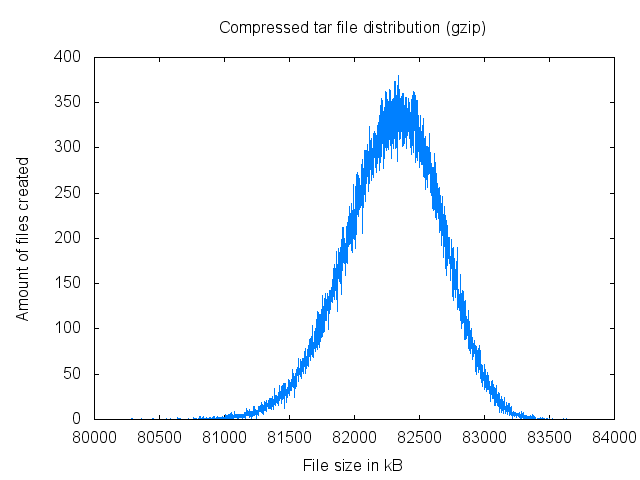
The file sizes range from 80282 bytes to 83605 bytes. A significant file reduction can then be obtained by carefully changing the input file order.
For the same number of compressed files, the distribution of the bzip2 files will be the following:

The files created range from 68532 to 68807 bytes, so the size variation is not significant in this example. Yet, the shape of the distribution is much more interesting, and its causes remain mysterious. For example, the same shape may be obtained by compressing the concatenation of the file contents, so the tar file format can be discarded. Also, the distribution curve keeps its shape by adding more data points.
Have a try yourself by downloading waf 1.6 (old branch) and the example.