Stop blaming the Chinese, the web is broken
Github was under attack at the same time as we were deciding to move the Waf project to it (informal poll results). The source of this particular attack is though to come from China, and such "cyber" problems are gradually taking a political dimension.
Yet, one may wonder why attacks can happen in the first place. Why is the web that fragile? Some suggest to encrypt traffic as a measure to mitigate the problem. Such a mitigation would only work if all sites and all users used mainly https.
A much more realistic solution for this particular issue could be to have web browsers disallow background requests to external sites unless the URLs is explicitly meant for that purpose. For example, if such requests were only permitted to domain names containing keywords such as "tracker" tracker.site.domain or "api" api.site.domain, then such attacks would then be prevented by design. The only drawback would be for advertisers as requests would become a little too easy to filter. We can bet that the idea will be rejected for backward compatibility reasons.
The Waf site is using https at least and the new padlock in the URL bar definitely looks nice. The confidentiality benefits are actually lower than we would like to believe though. Certificate authorities have been found to provide certificates to impersonate sites for a long time. Sometimes the matter becomes apparent, and finger starts pointing at people again.
Now, such basic impersonation would be easy to detect if for example site fingerprints were readily accessible instead of being buried behind layers of guis in web browsers. Certificate authorities would be less tempted to allow fake certificates to be created:
But even with easier access to the fingerprints and even with certificate pinning, the whole certificate system should be considered as already broken from its very core: trust only works when several crossing eyes are involved. It is well known that sensitive operations in banks require two people to open a blinded door for example. This principle has also been rediscovered in airplanes as well; they may require two people in the cockpit at all times.
A more robust scheme for the whole web would be to have site certificates signed by several authorities. For example, site certificates should be signed by one (or two) of the current certificate authorities (Comodo, Verisign, etc) and by another key with a certificate published on the registrar level. Then everyone would obtain the second authority through the whois information (elliptic cryptography does not require the keys to be very long). This second certificate could be used to sign DNS records as well: DNSSEC is not widely used yet, and no one actually cares.
Yet, the web browsers seem to do their best to keep the web as insecure as possible by focusing on features that have little value added for security while remaining essentially insecure and still feature classes of bugs that we thought long gone.
It is high time we stopped blaming the Chinese or the Russians: our systems are broken and we must redesign them.
Using strace to obtain build dependencies
Build dependencies are usually tracked either manually (input files in the build scripts) or through a dependency generator (a dependency scanner function in the case of Waf, or calling the compiler to dump dependencies). Another possibility can be to obtain the complete list of files accessed by the compilers by observing the system through an application such as strace. Here is an example of a strace output:
436242 open("/usr/lib/locale/locale-archive", O_RDONLY|O_CLOEXEC) = 3
436242 stat("test.out", 0x7fffd0ab8b00) = -1 ENOENT
436242 stat("/etc/fstab", {st_mode=S_IFREG|0664, st_size=458, ...}) = 0
436242 stat("test.out", 0x7fffd0ab8890) = -1 ENOENT
436242 open("/etc/fstab", O_RDONLY) = 3
436242 open("test.out", O_WRONLY|O_CREAT|O_EXCL, 0664) = 4
436242 exit_group(0) = ?
436242 +++ exited with 0 +++
The strace approach is used by the Fabricate build tool which is somehow advertised to be a better build tool. While this sounds like a brilliant idea in theory, strace is only present on some operating systems and not even by default. Fabricate will just silently ignore dependencies that it cannot find. And while more tracing tools exists (truss, dtrace), they are likely to require some adaptations.
Waf aims to be a reliable and portable solution so it will not depend on such a technique by default. There are also many cases where manually-written dependency scanners are necessary, for example in Qt file processing. Yet, I decided to play with the idea to see what an implementation would look like. Writing an extension to disable scanners and call strace appeared very easy to implement, but then scraping the strace outputs appeared to be a more complicated topic.
And indeed, compilers such as gcc can change directory (chdir) and spawn new processes (for example /usr/bin/as). Then they can open files using relative or absolute paths, and not all attempts are successful. As a result, interpreting the strace outputs requires to keep track of the current working directory for each sub-process executed. The data can also grow quite large, so it is tricky to process efficiently. Iterating over output lines by means of a single regular expression seems to do the job at least.
The following trace extract shows the system calls of a shell script (pid 436292) changing its directory to '/etc' and calling command to copy files (pid 436293):
436292 execve("stracedeps/foo.sh", ..
436292 chdir("/etc") = 0
436292 stat("/sbin/cp", 0x7fff6e640c20) = -1 ENOENT (No such file or directory)
436292 stat("/bin/cp", {st_mode=S_IFREG|0755, st_size=150912, ...}) = 0
436292 clone(child_stack=0, ..) = 436293
436293 execve("/bin/cp", ["cp", "fstab", "../home/user/test.out"],
436293 open("fstab", O_RDONLY) = 3
436293 open("../home/user/test.out", O_WRONLY|O_CREAT|O_EXCL, 0664) = 4
436293 exit_group(0) = ?
436292 exit_group(0) = ?
Then, double-quotes characters in file names will be preceded by backslashes in the strace outputs, so that an additional transformation is needed. An adequate regexp to match a string containing double quotes is "([^"\\]|\\.)*": a string is a sequence of either any character except quotes/backslashes, or a character preceded by a backslash. I have actually reported an issue regarding this point to the Fabricate issue tracker regarding missing dependencies.
436323 open("waf/playground/stracedeps/\"hi\".txt", O_RDONLY) = 3
While the new Waf strace extension can return interesting results, the build performance takes a major hit. A C++ benchmark build taking 56s would then take 1m28s by running commands through strace, and 1m31s with complete dependency processing. I would try with dtrace on FreeBSD to see if the tracing can be faster, but it seems dtrace requires root privileges to run at this time.
Cost of starting processes on multiple cores
Ten years ago most computers had one or two CPU cores and quite a few of us were hoping that performance would not be a concern in the future. News have been a bit disappointing, as processors may well have more cores, but they are not getting much faster. New Python interpreters would overcome the weaknesses of CPython, but they are not as fast and usable for the time being (Pypy, Jython, IronPython). This slower progress has also helped the development of cloud solutions as older hardware usage remains profitable.
Software is growing in complexity and the build tools have not escaped the trend. As anyone can write a build system, quite a lot of tools have been written, but only a few new ideas have appeared over the years. Waf has been using a reverse dependency graph since about 2006 for example, and small enhancements such as cleaning up stale files as part of the build were already implemented as extensions years ago.
An innovative idea currently explored in wonderbuild is to write the build scripts as Python generators in order to limit the amount of "busy wait". It seems to yield interesting performance benefits on benchmarks at least. The Waf source code can be modified to use generators (modifications in Task.py and Runner.py) but the performance benefits are not significant, and writing all Python functions as generators is complicated. The Python asyncio module is also limited to Python >= 3.4.
At least, experimenting with the benchmark files has revealed that a significant amount of time can be spent in spawning processes. Build performance used to degrade approximately linearly with build tool performance years ago on a single core system, but now the effects become excessively clearly visible with multiple cores.
The following picture illustrates the hardware thread activity on an 4-core hyperthreaded CPU (i7-4770K) during two builds (link to the benchmark). The first build is unable to spawn sufficient processes to keep the hardware fully busy. It also appears that the occupancy degrades over time; this is probably due to the growing memory usage of the Python process.
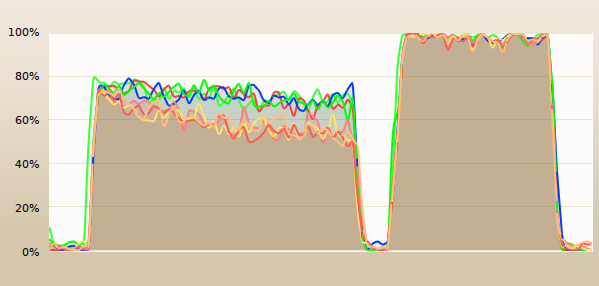
The second build was obtained by enabling a new Waf extension called prefork in the build process. Instead of spawning processes as needed, the extension would start slave processes, and reserve a pool of connections to them. When needed, threads in the build process would just call the slaves to launch the compiler processes for them and to return the exit status and any additional text produced during the execution (build outputs can become garbled if all processes write at the same time).
The second build on the picture was nearly twice as fast as the first one (30s -> 17s), and the difference on larger benchmark builds seems to improve (2m7 -> 0m55). Yet, this is unlikely to help so much in practice: on the Samba builds the gap is much smaller (~5%: 1m50 -> 1m45). This is probably due to the build tasks taking a much longer time to complete.
I would be curious to experiment on hardware featuring a lot of cores though (128? 256?), so if you can access or provide access to such hardware, feel free to drop a comment, or to join the discussion on #waf on freenode.
Pypy 2.3.1 versus cPython 2.7.6 on very large builds
A good build practice is to keep the count of build tasks to an absolute minimum. It implies fewer objects to process (reduced pressure on the Python interpreter), less data to store (data serialization), and fewer processes to spawn (reduced pressure on the OS). If is therefore a good idea to enable batches if the compiler supports them (waflib/extras/unity.py and waflib/extras/batches_cc.py for example).
Although very large builds should be uncommon, it can be interesting to consider how the Python interpreter behaves at the limits. Here is for example a few results on playground/compress for a large amount of tasks:
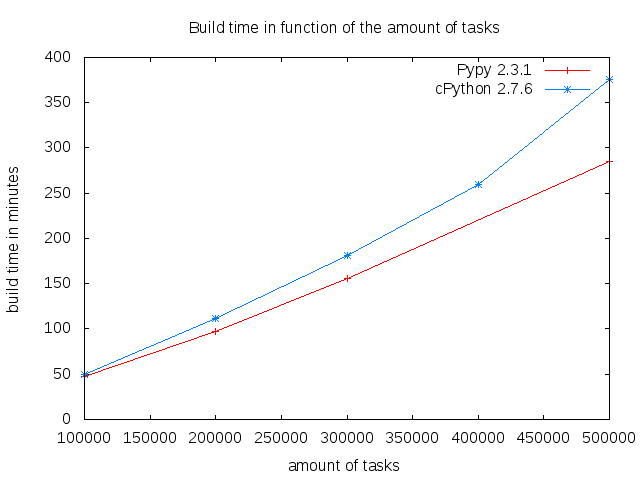
The runtime difference between cPython and Pypy becomes noticeable at approximately 100K tasks (1 minute). It then stretches to about 90 minutes for 500K tasks. One explanation for these figures can be found in the memory usage:
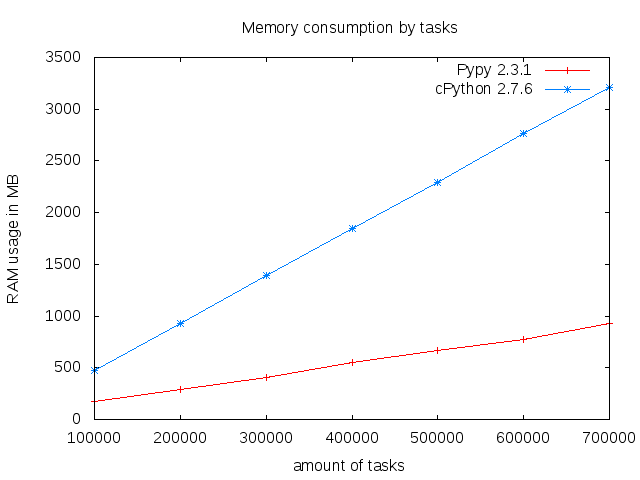
Since the Pypy interpreter requires much less memory than cPython, it is more likely to remain efficient with a high number of objects.
Linux filesystems for build workloads
Linux systems include several filesystems by default: XFS, JFS, Ext3, Ext4, reiserfs3. These filesystems have certain characteristics, with some known to be better at small file handling (reiserfs3), others at big files handling (XFS), or featuring annoying quirks (long filesystem verification time on Ext3).
I tend to prefer XFS because the Ext2/Ext3 verification times (fsck) can take a very long time to verify (this is just unacceptable on production environments). After seeing XFS performing poorly on a file server (extremely long file deletes), I have decided to take actual measures to make myself an informed opinion.
The scenarios below represent typical operations on servers running on a build farm: file writes (building the software), file deletes (clean builds), and file system verification (unexpected shutdowns).
The numbers have been obtained on an Ubuntu 12.10 workstation freshly installed (Quantal Quetzal) having two mechanical hard drives. A large build folder of 55GB containing source code and build artifacts was used in the tests below (350000 files spread in 19000 folders). The data was first copied to a freshly created filesystem, then the filesystem was unmounted and verified (fsck -f where applicable), and then all the files were removed from the filesystem. The very large fileset was essential to get relevant data, and best times of 2 runs were recorded.
File writes
This test represents the time to copy all the files to the initially empty filesystem from a separate hard drive:
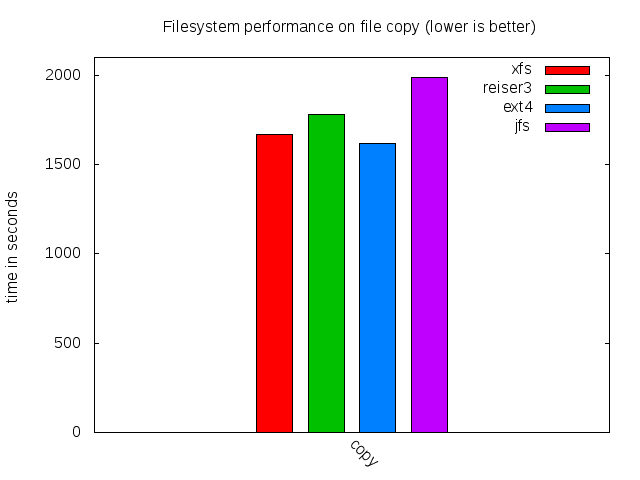
Filesystem verification
A weak point of Ext3 on servers is that verifying the filesystem can take a long time. This verification can happen if the system was not switched off properly, and can cause unwanted downtimes. I was suspecting that Ext4 would take a verification time too, but I was pleasantly surprised:

File removal
File removal has been a weak point of XFS for a long time. Removing a few terabytes of data can take such a long time that I sometimes consider replacing rm by mkfs. I was hoping that the version of XFS in the kernel 3.2 would perform much better due to the recent optimizations. The following represents the time to remove the directory copied previously:
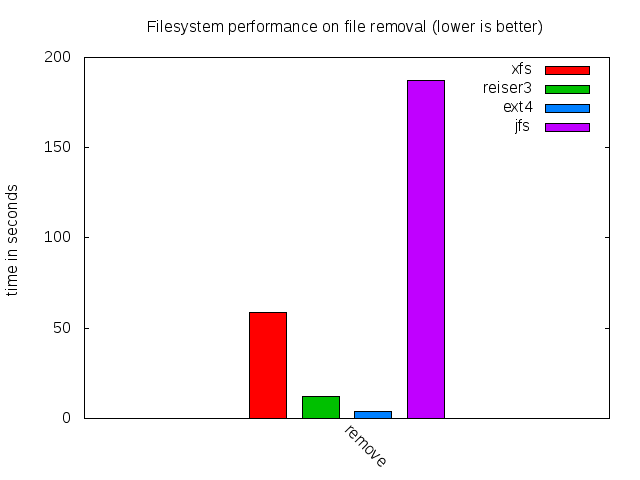
Conclusion
For build servers and related fileservers, it makes sense to prefer Ext4 to other filesystem types. XFS was a good solution against Ext3, but this is not the case anymore.